What is a company? A Product Management Perspective
The relationship between a product and a company is not obvious. Financial statements are rarely broken down into products and the ultimate drivers of the value of a product are not obvious for the overall company. I try to tie it together here.
Since I haven't studied business, my business knowledge is pieced together. For things like cost of capital, public and private equity, tradable vs. non-tradable debt or "alpha" the basic mechanics plus why they exist make sense. (Also the beauty and creativity of the concept of a legally limited entity is clear - e.g check out this piece)
But, it took me a long time to understand the relationship between product and company - from an operating business perspective. Not, for say a holding company.
An operating company generates revenue from the selling of products. That is why a product is the starting point and the unit of analysis to get to the core of it.
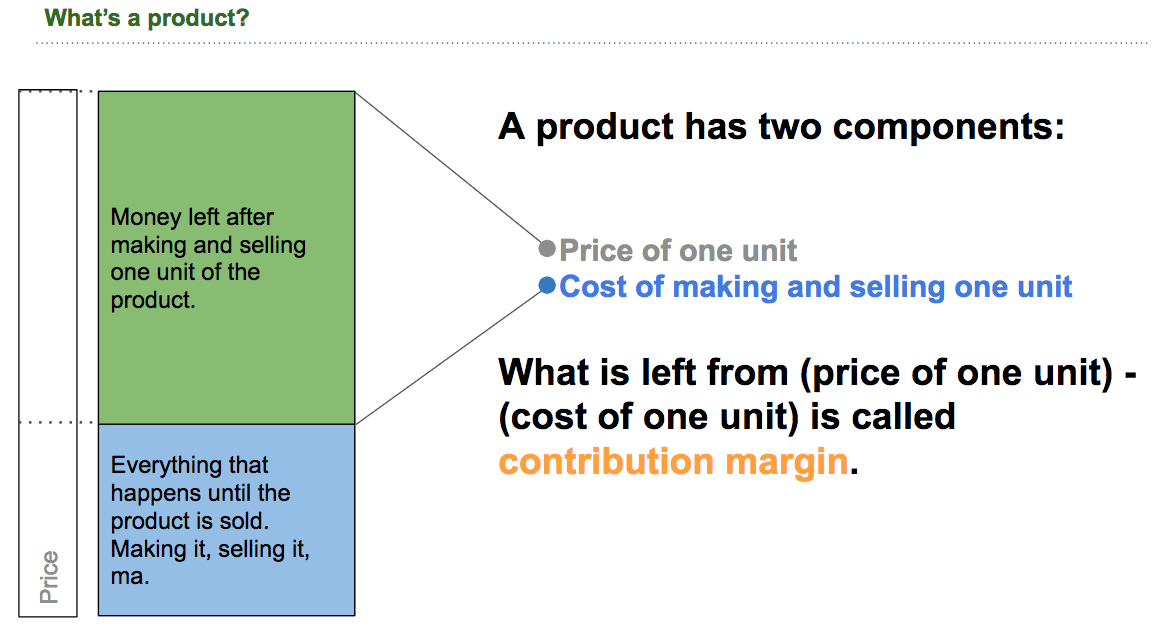
What is a product? Whatever has a price.
We define a product as what brings revenue to the company. For example, the product of Facebook is a click on an add. The product of a bank is the fee or interested charged on a loan.
A feature - in contrast to a product - does not have a price but is a characteristic of the product. For example, "groups" in Facebook might bring more people to Facebook or make them spend more time on Facebook which increases the odds of people clicking on a link. But, the number of groups on Facebook is irrelevant for it is not directly tied to the price per click Facebook charges it's advertisers.
A feature of a loan might be that repayment starts only after 5 years. If for example the loan is targeted at people starting a 5 year doctorate program. So that repayment start date is a feature, but does not directly change the revenue. (Yes, I understand time value of money but that is accounted for in the interest rate).
Another way of formulating what a product is, is (number of product) * (price) = revenue from that product. The product is whatever has a price and therefore generates revenue.
The two features of a product
Basic product costs...
Now, since the unit of analysis is the product we split costs between "costs per unit of product" and "overhead".
This obviously depends on what you are selling and how you sell it. For example, if you are McKinsey & Co. your product is a consulting contract. The costs are the salary of the people making the analysis and travel expenses. The cost of sales is maybe the membership of a partner in a high level working group, the golf club membership, travel and hosting expenses.

If you make iPhones, than the product is one phone. The costs are the components to make (< 400$ check out this analysis), and other cost associated with production and sales and marketing.
In our example above, if you are Facebook, the major cost is having the users that click on the advertisement (which is the product because it has the price money).
From an accounting perspective, this is akin to the variable costs. The logic of the variable costs is that they increase with additional output. So, if you build a car, than you got to buy 4 tires for every car. So the more cars you sell the more tires you need.
... and more tricky product costs
The accounting perspective on product cost is much more straightforward than it is in reality.
Say, you offer the customisation of a hardware product at a low price. The customisation price either exceeds the labour costs of doing it - than it is its own product.
If it does not than it is either "overhead" or "unit costs".
But which one - this depends on two questions: "Would you sell less units if this feature was not offered?" - if yes, than it is product costs and part of customer acquisition costs. If not, than it is overhead. If it is overhead, than this is part of company strategy either implicitly or explicitly.
A similar case are support and service teams - from experience we can see that the "does it increase units sold?" test often determines service quality. Either:
it has price, than it is a product
it increases volume sold - than it is part of customer acquisition costs
it is neither, than it is overhead
Products that operate in a low competition world - Internet, mobile phone, telephone - have low customer support/services. This is because having it will not drive units sold or would be an extremely expensive way of doing it. You need an internet connection. Once you have it you are in a long term contract so spending money on support is pointless.
The alternative is true for a company like Zappos. Retail depends heavily on customers buying repeatedly. Hence, every support interaction can be associated with volume increase, so it is a cost that drives volume sold and therefore accounted to the product in the customer acquisition cost bucket. A metric to use could be: "share of customers that order in 6 months after a support request" - compare this to the general re-order rate and you have a first meaningful piece of data.
Contribution margin
The difference between the price of a product and the cost of that product is the contribution margin. Revenue per unit of product - Cost per unit of product
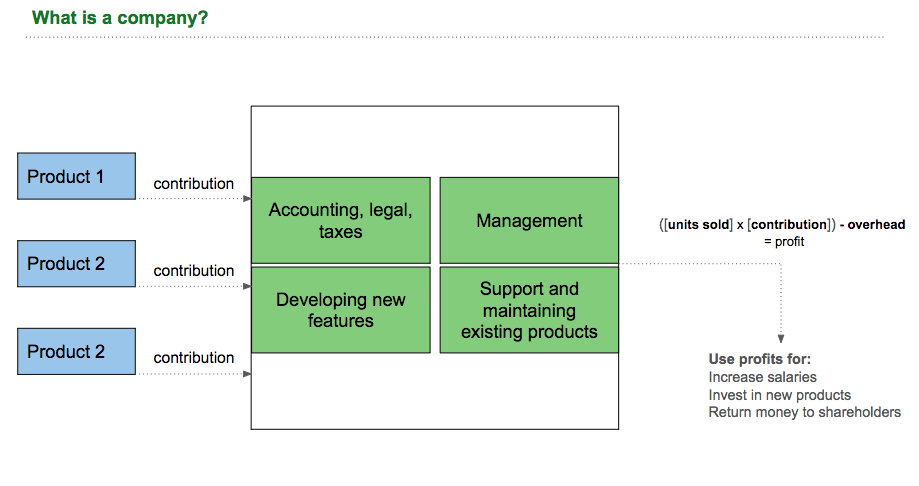
What is a company? The sum of its products
In this framework of analysis, a company is simply a collection of the products that it sells. For a company to exist, it either needs to be profitable or get funds by taking loans or selling parts of itself (= investors on board). In the short and medium term investors might sometimes care more about revenue or user growth than they care about profits - but in the long run profitability is king, because cash is.
That means, all the costs of a company that are not part of the product costs must be carried by the contribution that each product makes.

In other words: you have to pay everything that is not directly linked to a product from the contribution you get from other products.

The amount of money available simply is the contribution margin multiplied by the number of times you sell that product.
Given this scenario, two things become apparent. The goal of the overall management (on the left) and the goal of a product manager.
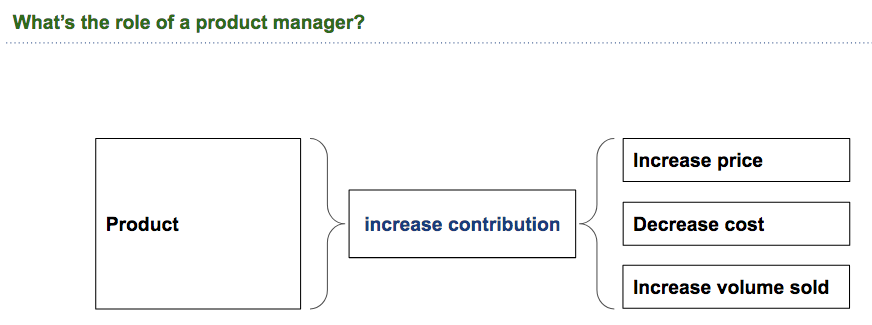
Product management: Increase the contribution
Given this approach to a company, the role of a product manager becomes relatively straight forward as well.
Essentially, increase the contribution of the product to the company. There are just three tools to do that:
increase the price,
decrease the costs
increase the volume sold.
Product Management is increasing the contribution of the product to the company
(Besides discussions about launching a new product. Separate piece coming on that.)
In this light, a typical discussion, for example, if a certain feature is worth it can be discussed in a useful framework: Will it increase the volume? If so how?
By reducing lost deals? (how many do you loose right now because you don't have the feature?)
By bringing in new potential customers? (does marketing know?)
Hope this is useful!
Lecture Slides: Product Strategy at HWR Berlin
Slides from a recent lecture on product strategy at the HWR (Berlin School of Law and Economics). Focus on unit economics/contribution margin and the win/loss as an analysis tool.
From time to time I do talk and lectures on IoT and Product Strategy. I throughly enjoy this because it focuses my to structure and formalise my thoughts.
Most recently I taught two classes on product strategy at the HWR (School of Law and Economics) in Berlin. The topics are a general introduction to product management with a focus on unit economics - from my perspective the crucial topic in product management. In addition, we discussed win/loss analysis as an analysis tool that pinpoints the problem fast.
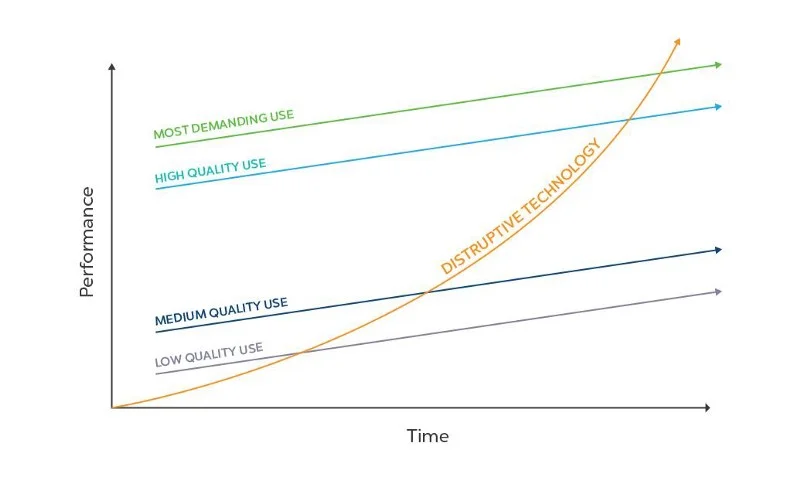
Disruption theory applied: Bluetooth low energy vs. RFID
In this piece I use Michael Clayton's disruption theory to predict the future of the technology battle of Bluetooth Low Energy vs. active and passive RFID. The frame of analysis is the Jobs to done framework on a technology level.
This is an edited version of similar articles I have posted on LinkedIn and Medium previously. If you have read those than no need to re-read this one but I am happy if you share it.
The starting point for this piece was trying to apply disruption theory forward looking. Because, the strength of a theory is its ability to forecast the future.
What is the internet of things?
At the core of the Internet of Things lies the challenge of getting information from sensors to the internet. The requirements for the underlying communication technologies vary widely on the common criteria of power consumption, latency, throughput, distance covered and resiliency.
However, one thing is clear: wireless technologies are leading the charge both in the retrofit market as well as the integrated market.
This article seeks to apply disruption theory to the competing connectivity technologies in the internet of things. I look at the competition between active RFID (typically the frequency bands 865–868 or 902–928 MHz) and Bluetooth Smart (or Bluetooth Low Energy) — both means of transferring information wirelessly. Active RFID has been around since the nineties, and Bluetooth Low Energy has been part of the Bluetooth Standard since 2010.
Conceptual frame: jobs to be done
The frame of analysis: jobs to be done
In order to frame the analysis appropriately, the realm of evaluation is described using a “jobs to be done” approach.
Job one: Knowing where things are at what time. Tags (for Bluetooth, these are often “beacons”) built on either technology send out a signal that allows the reader to estimate where the tag is. This is done by comparing the strength of a signal received with the strength of which it was sent out and using the difference to approximate distance. For example, if a tag is stuck on a forklift and the forklift enters an area with a receiver — say, a loading dock — the location of the forklift can be approximated.
Job two: Transmitting sensor data from a tag to the receiver. For example, a tag attached to a conveyer belt with a temperature and vibration sensor that transmits the information to a receiver. From this, valuable conclusions could be drawn: for example, whether the conveyer belt is overheating or running at an inappropriate time.
Different types of disruption
Disruptive technologies are divided into two: “low end disruption” and “new market disruption.”
Different views on the disruption theory. Read: https://en.wikipedia.org/wiki/Disruptive_innovation
Low end disruptions work in a similar pattern. The initial entry point is a group of underserved customers, typically at a low price point that makes these customers unattractive for incumbents. That is why these customers are typically underserved in the first place.
Then, as the technology continuously improves, it moves to more complex and higher value applications replacing the incumbents. Classic Clay Christensen examples include the Mini-Steel Mill or the Digital Synthesiser. The same effect Mahatma Gandhi describes in “first they ignore you, then they laugh at you, then they fight you, then you win.”
Since RFID and other technologies which do comparable or similar jobs to Bluetooth Low Energy and have been around for quite some time, this is not “new market disruption.” For the sake of argument, we’ll exclude the technological advancement of a wireless technology working natively with the ubiquitous smartphone.
Does Bluetooth Low Energy fit the low-end disruption theory?
As the Disruption Theory suggests, initially Bluetooth Low Energy served customers that have not been served by incumbent technologies. Indoor wayfinding is possible with RFID tags and dedicated handsets. Consumer applications like Bluetooth key fobs are similarly functionally possible with existing solutions. But both are on the bottom of technology applications and not profitable.
The key question is whether Bluetooth Low Energy will move up the performance stack and endanger incumbent technologies, in this case active RFID.
Job to be done 1: Location
Arguably, the current performance of active RFID and Bluetooth Low Energy is relatively similar. The question is whether and if Bluetooth Low Energy will improve significantly and move up the stack. Today, from a technological perspective, this seems very likely for the following reasons:
First, integrating additional sensors like acceleration and inertia at a low battery cost will enable much better contextual interpretation of the Bluetooth signal, resulting in higher functional accuracy.
Second, Bluetooth 5 is mesh ready which means that the cost of receiver nodes drastically drops. The mechanism is this: Bluetooth nodes can act as both a receiver and a broadcaster of a signal. As the cost of Bluetooth hardware is extremely low given the economies of scale of the smartphone supply chain, it is possible to find affordable (sub-50 USD) battery powered receivers capable of forwarding information to a central hub via mesh networks.
Job to be done 2: Sensor data
Transferring information from a sensor to a receiver is a commodity job. In the large majority of use cases, latency requirements and throughput volumes are low. Bluetooth Low Energy boasts a convenient entry point due to the low costs of the sending device. This is accentuated by its integration into smart phones.
First of all, this means that data retrieval from sensors can be handled through smartphones without the need of an external infrastructure, further reducing costs.
Second, lower energy consumption per data volume transferred increases the potential for sensors.
Finally, sensor information and location information can be easily combined in use cases where the receivers are mobile devices.
Starting at the low-end, will BLE move up the stack?
Right now, there is no question that Bluetooth is still far from the advanced industrial solutions offered by RFID across verticals and specialised use cases.
The key question is: why should Bluetooth Low Energy not move up the stack and disrupt the incumbents? Given the affordability, capability and growing popularity, the only unknown factor for Bluetooth’s disruption in the Industrial IoT is time.
About me: formerly core technology lead, now a strategic advisor to Kontakt.io. In the past, I have worn many hats including growth manager, advisor, and board member.
Operational startups sales
Written for a friend of mine, I sum up sales strategies very briefly. In a piece that has taken me 55 minutes to write.
Once again, the following is written fast for an audience of one. Not a polished blog port, more a “if I write this in an email, I might as well write it as a blog post”. So this is a fast take, that does not claim to be better than what exist. If you want to talk about this write me a mail: s.buenau@gmail.com
This is about b2b sales, three things upfront:
sales does not mean to be a pushy person but persistent and somewhat quantitative
sales = revenue
all sales need to be in line with the legal frameworks
To me, sales breaks down like this:
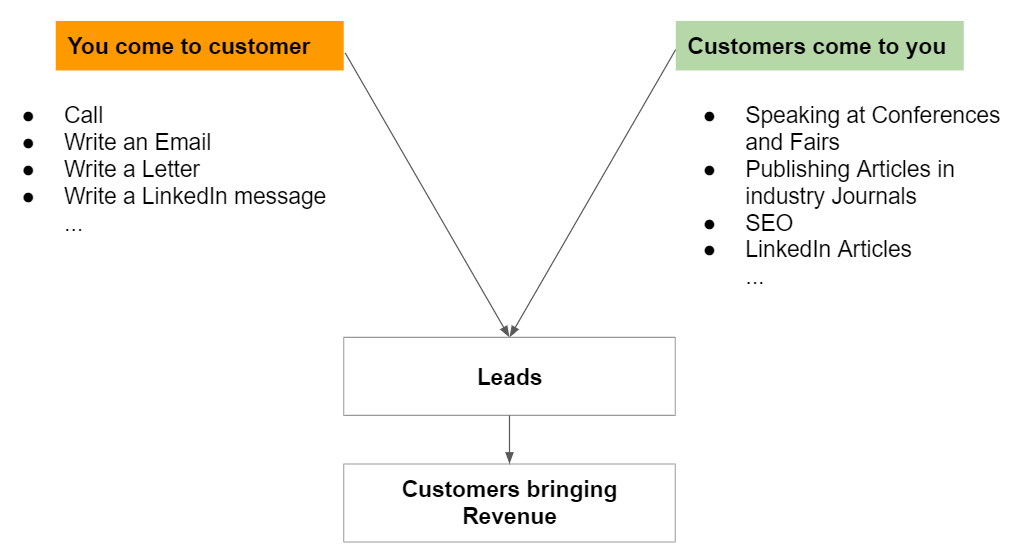
You need to get people interested and qualified to buy your product or do a transaction (if you are a marketplace) or whatever it is that makes the revenue. You have to strategies: people come to you or you mtry to make them come to you.
Playbook for “make people come to you”
SEO. This has three components:
Make content: Getting an article written on a defined topic costs roughly 40-80 Euro per 500 Page Article from a writer, on workgenius (which I use) or upwork. Ideally, you write the first 5 Articles. The average article takes you about 3 hours. The rest of SEO is technical, making sure the headlines are correct and the structure is fine.
Technical optimization: This is straightforward stuff that an online SEO tool will help you check. Basically, formatting of the headings, page meta text and mobile ready. Obviously, in hyper competitive spaces this matters a lot but in general it is more table stakes.
Get backlinks: This is asking people to place a link to you. Nobody will does this if you do not ask and just placing links on quora is not enough.
Overall, this is 1 week project for you as the a leader, excluding writing the content and the product pages.
Speaking at Conferences and Publishing in Journals
This comes down to contacting the conference and the journals about a particular talk/piece that you have and finding out if it is of interest. That means you need to get a list of all relevant journals and conferences. Than you need to find the names of the people that matter there. Than you need to email or call them. Making the list probably takes you like 1 hour. Then finding the people that matter and their contact details takes somebody another hour or you outsource it to workgenius. Then you pitch and find out why you do not get in.
LinkedIn Articles just means writing the content.
Playbook for “come to people”
This is very simple. If you have defined group for either companies or people (depending on your go-to-market) it probably looks like this.
Say you have a group of companies by their branchencode (industry-id) in Germany, you go to neugeschäft.de and you buy the relevant data. That costs you about 30-180 cents per data set (name of company and CEO).
So if you need all companies in metal product in German with more than X people you might get 1200 results and this might cost you 2 Euro per piece so now you have spend 2400 Euro but the market is clearly defined. If you want an into to neugeschäft, let me know. I have worked with them a lot
Alternatively, you have somebody (again, I use workgenius) research the relevant companies. You pay a bit less (30 to 40 cents) and might get more information like phone numbers and email addresses.
Next you contact them - a letter costs a 1,20 Euro, phone specialists that you hire by the hour do 20 calls an hour and cost about 60 Euro, so that is 3 euro per contact, email when legal is super cheap.
But essentially, that is it. A full contact costs you somewhere around 3 Euros. Now the question is just to contact them.
There are only two potential reasons: you are not talking to enough people or your product is not good enough. Both are your problem but you no which one you are having.
Once you start contacting, I highly recommend setting up a basic win/loss analyis from the first contact onwards so that you know why you are not doing enough revenue. In addition, the cost of lead acquisition is a key component of your business, so trying to measure that at least somewhat is important.
Very important: Being creative about how you get to your customer is EXTREMELY important. Without a customer the products is not generating revenue and not proven to an investor. Getting a senior advisor from the industry on board, understanding how to get in front of everybody, influencing legislation - there are many areas where competitive advantage can flow from.
Check this out here: https://www.sbuenau.org/blog/2018/2/20/ignore-the-win-analyse-the-los-for-product-managers
First principles SEO & Online Search
Unedited article about how SEO and internet search works. If you can bear the bad drawings and writings, you might find it useful.
Yet again, another fast written and unedited article. I don’t mean to make light of the massive math/statistics/engineering achievements behind what I am going to run over in the following text.
We know that the internet is three things:
1. A number of computers “servers” that are connected to each other and connected to households - via phone lines, fiber or whatever.
2. A system of asking for websites from the servers with easy to remember names “www.spiegel.de”.
3. A method of structure information that is compelling, a combination of text, videos, clickable things and whatever else you find on a website
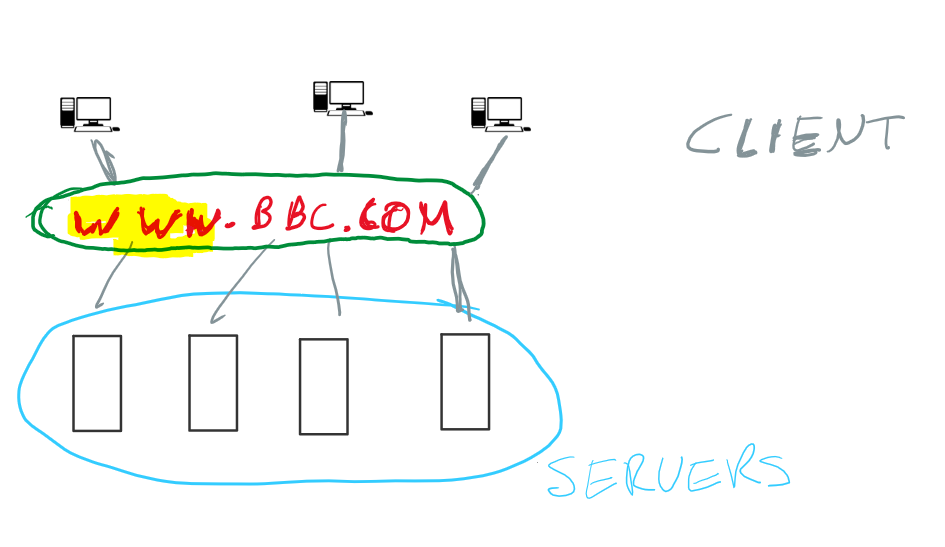
However, there is more. Not only can you get to a website by knowing it’s address, websites are also linked. On website can refer to another website and make it easy to navigate there using hyperlinks.
Links are not unique to html, the language of the internet that this website is written in, they were already used in Gopher, arguably even mentioned as a concept in “As We May Think”, the famous Vannevar Bush essay. They turn out to be extremely important.
What problem does a search engine solve
We now know, that there are only two ways of accessing content on the internet: via a link or if you know the address directly.
Initially the web was more about “discovery” than “search”. Discovery means that I have less of a target that I look for and more get an understanding of what is there. Often this is “categories”. A current day example of a strong discovery product is Instagram or Pocket.
This is the time when lists are the dominant way to explore the internet. Makes sense as you know that you are interested in cooking or woodwork but don’t have a specific query in mind so a list of the best woodwork sites helps you well. You can think of a portal as a more dynamic form of a list.
Now, as the web matures users start to know that there is probably content out there, the problem becomes finding it. Compare this: looking up “woodwork” in a list of hobbies fairly fast and pleasurable for a human, finding an article on “the best courses on woodwork in Oregon” is no longer something works in a list. Should I look at the list for courses, or the list for Oregon or the list for woodwork?
So, what is search? Initially, search is a query, i.e. what you are looking for. Then it is a set of possible answers.
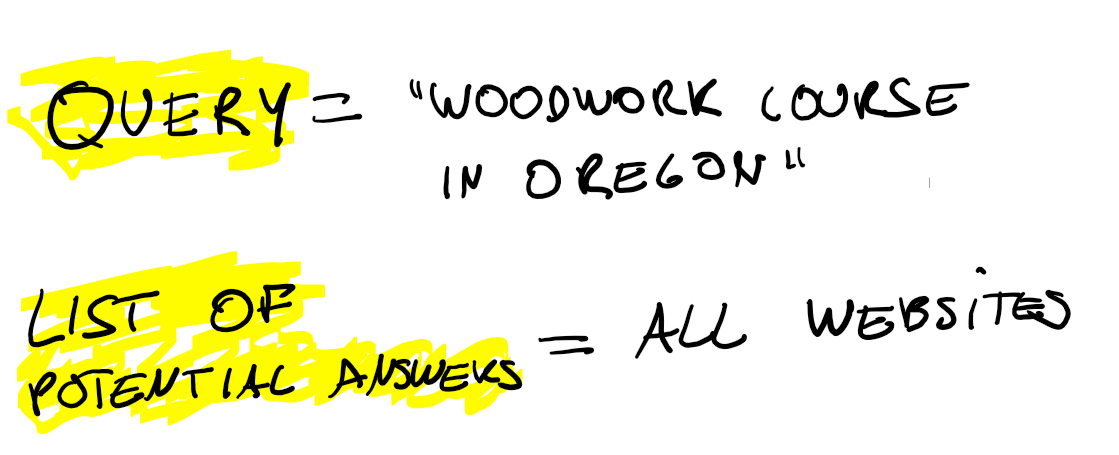
Given this, the exercise becomes how can we sort the potential answers in a way that they match what the users want. One extreme solution you could think of would be to serve the websites randomly and just take not of which one the users clicks. Than, next time somebody search for the same website rank this website highest.
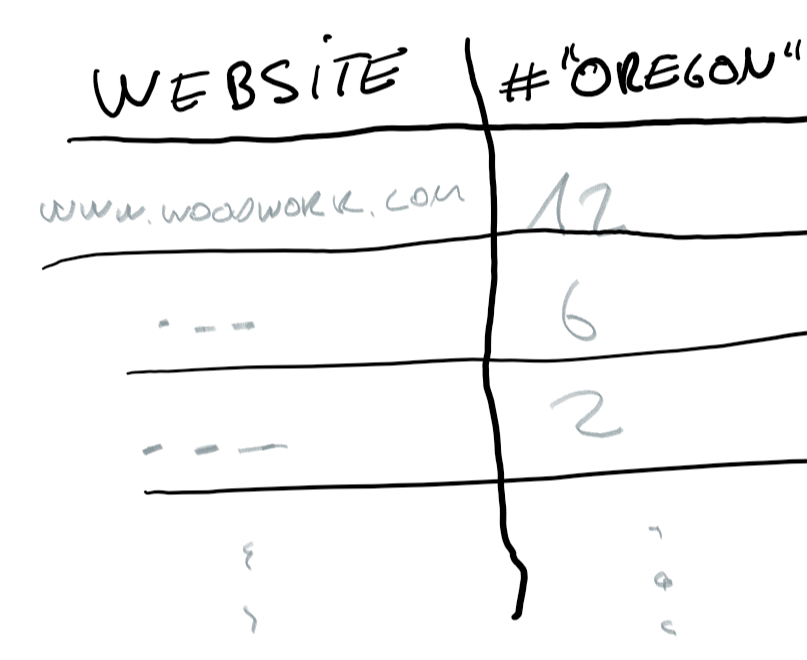
A better version would be, that you send around a robot that counts city words on websites. So when the robot is done crawling through the whole internet a list comes out like this the picture on the right.
Basically a table that contains a list of how often “oregon” appears on a certain website. Now you search algorithm might breaks apart the input, notices that the user ask for something containing oregon and generate a ranking of websites based on this algorithm:

Now, there is a certain amount of algorithmic stuff you can do on a website. For example, you can give a weight to words that are in a headline or you can try to discount words that sound like a list of cities and elements like this. There is massive complexity in building up the database we mentioned earlier. Because that means extreme amounts of crawling information and synthesising it.
This type of information relies entirely what is on the site, in SEO circles stuff that relates to what happens on the website is therefore called “on-site”.
However, an external and therefore potentially more objective variable to output the liklihood that a given website matches the query of user is the number of links pointing to a website.
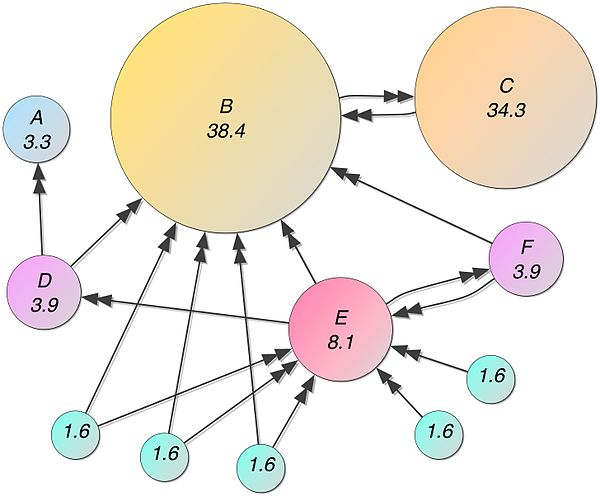
The math (“eigenvector” behind this I cannot explain, yet intuitively the importance of a site is increased by the number of sites point to it. That requires you to have a complete map of the internet.

Now, in access of the on-site and the of-site criteria, a third input for the ranking of potential results could be “context” a made up example could be that if people google “fish” on Saturday night, this is more likely to be a search for a fish restaurant, whereas if it is googled in the late morning, this indicates a query for biological content - in this example the context is the time at which the query is made.
Google is known to use other factors such as “is a website optimised for mobile devices”. This is essentially a political decision by Google to use a factor like this as an input.
In general, the SEO industry is full of a lot of advise on the google algorithm. Nobody really knows what is considered heavy - naturally because it is not in the interest of google to promote the website that follows most specifically to their algorithm but rather give rough hints on what matters and what does not.
Matt Cutts used to be the speaker of Google search, it always reminded me of central bank announcement. Not fully confirming rate increases in the future but pointing towards a direction pretty specifically. In generally, SEO is quite straightforward: guess what google cares about and implement that. Be it getting links from reputable third parties, content from writers or a mobile ready website.
How google will get a problem
This relates to google search, less from a business (=profitability) perspective more from a user perspective.
“Search” is no longer a process of discovery. Search is extremely profitable as a way of advertisement because it expresses intent, you are searching something so you want something. If that notion of expressing something through a means of searching goes away, than a problem arises.
My guess would be that this happens because specific types of content get aggregated. For example, capterra takes over comparison of software features, pocket and medium take over content and amazon takes over product search.
“Relevancy definition changes” to me, this is the most interesting. Relevancy relies on content and links. If this where to change, for example because a micropayment of some sort is established, the paradigm becomes worth less.
“Means of input changes” if search moves to voice, this is not a probem since voice can be made text quite easily. But if search is broken up into particular contexts, as written above this does become a challenge.

Question: Is it possible to prevent the extraction of data that I see in my browser?
Where is a file that I look at on the internet.
This article has two aims:
Provide the causality that lead to the answer of the above question
Test if my windows surface pen is useful to make these articles
Let’s go. Spelling will be wrong, grammar not beautiful.
On the left side of this horrible drawing we have on thing called a “Server” on the right we have a something called a “PC” with the apostrophes missing. Both are the same thing. The only difference is that a “server” is specialised to provide content.
That means it has for example especially fast hard drive to access all the files stored on it but maybe a really bad or now graphic card because it never runs video games. It is called a “server” because the purpose of a server is to serve files to other computers.
On the right hand side we have a “PC”. A PC is also a computer but it is for personal use so it could be lightweight but still have a graphic card to support video games. These two are connected via the internet. This is drawn with magic colours because I will not go deeper into the components of the internet, like what the www. is and what tcp/ip is but we will just accept that the PC can get data from the server.

Now, if we look on the server there are different types of files: “spiegel.webseite”, “funny-cat.video” and “financialmodell.excel”. From our own computer we know that the ending indicates with what program a different type of files is opened.
So, what is a browser? A browser is two things:
first of all it is programm specialised in a type of file from which websites are made
tools to navigate the internet
The tool to navigate the internet is the address bar. You type in from which computer to want which file. When you type in www.spiegel.de what you are saying is “give me the homepage file for spiegel” then the browser displays that file.
But you could also get the file of the Spiegel and not look at it in a browser but look at it in Word Pad. That would look like this:
This is not really useful. That is why you open the website file with a web browser. Similarly, if you open a video file not with VLC player but a Word Pad the result is also not what you would like.
Now, that we know that the Browser is a tool that looks at a certain type of file in a nice way, lets look at our question again. “Is it possible to prevent the extraction of data that I see in my browser?” - since the browser is installed on your own computer and is just a way to look at a certain type of file, the question is: where is the file? On your computer or on the server?
Correct, it is on your computer, it must be because that is where the program is you use to look at the file.
In essence, a large part of the POINT OF THE INTERNET is to make files on other computers (servers) accessible through things like hyperlinks and visual presentation (Mosaic, Marc Andressens first company did the first visual web browser).
One way of making data harder to use for the recipient is to make it “unstructured”. The most common example of this is well known.

The purpose of this is to give information that is hard to understand for a computer but easy for a human. Captcha stands for “Completely Automated Public Turing Test To Tell Computers and Humans Apart.” In this system the data is transmitted as an image that is difficult to read as a computer - yet it is still transmitted.

Altran & Aricent
Super fast written article about Altran, the company that just bought Aricent, backed by Sequoia Capital. Excuse mistakes, this is done in sub 45 minutes.
This is a blogpost that was initially meant to be a note for myself. I am again writing it as a blogpost without a lot of care. I plan to spend about 45 minutes on this, I will also take positions that might be wrong.
A friend of mine recently started working at the combined company following the merger of Aricent & Altran.
Aricent: Launched in 1991, as a split of from Hughes Electronic with Sequoia. That in and off itself is really interesting, since it is a type of deal that does not feel like Sequoia from today’s perspective. Hughes Electronic does tie back to the Hughes corporation, which is the company run by Howard Hughes (the model for Tony Stark and other movie Characters.
My main question is: What was the Sequoia Investment thesis in this company? Was this a product company that moved to a service provider?
Altran: Launched in 1982, by two Frenchman who where at KPMG prior. Or more accurately they were at Peat Marwick before which is the P and M in Klynveld Peat Marwick Goerdeler (KPMG).
What is very interesting in light of the merger with Aricent is that Altran has been growing through M&A in the past. Starting in France than across Europe and the US, including buying the assets and brand of Arthur d Little. From Wikipedia: “In the second half of the 1990s the company was acquiring an average of 15 companies per year.” This is quite an astonishing number. I would love to understand the rationale better.
Business Model:
Altran is a service provider. So in essence what a service provider does is sell time of its employees. There are essentially two ways to do it:
bill time and material like a law firm
bill based on a certain delivery, like a project deliverable
share project risk like a take share of the revenue generated from the product
In all cases the IP of the work ends up with the customer. The costs are basically your employees. In the most simple form the business model depends on billing the customer more for the labour than you pay labour.
Outsider perspective
If the understanding of the company is correct, then Altran should be driven by the availability of skilled labour and the the price it can therefore set for labour. Capture a surplus in high times (now) and remove people fast in a downtime (2008 - 2011 or so)
If I just look at 2017 in the annual report I find this data (screenshot from the annual report):
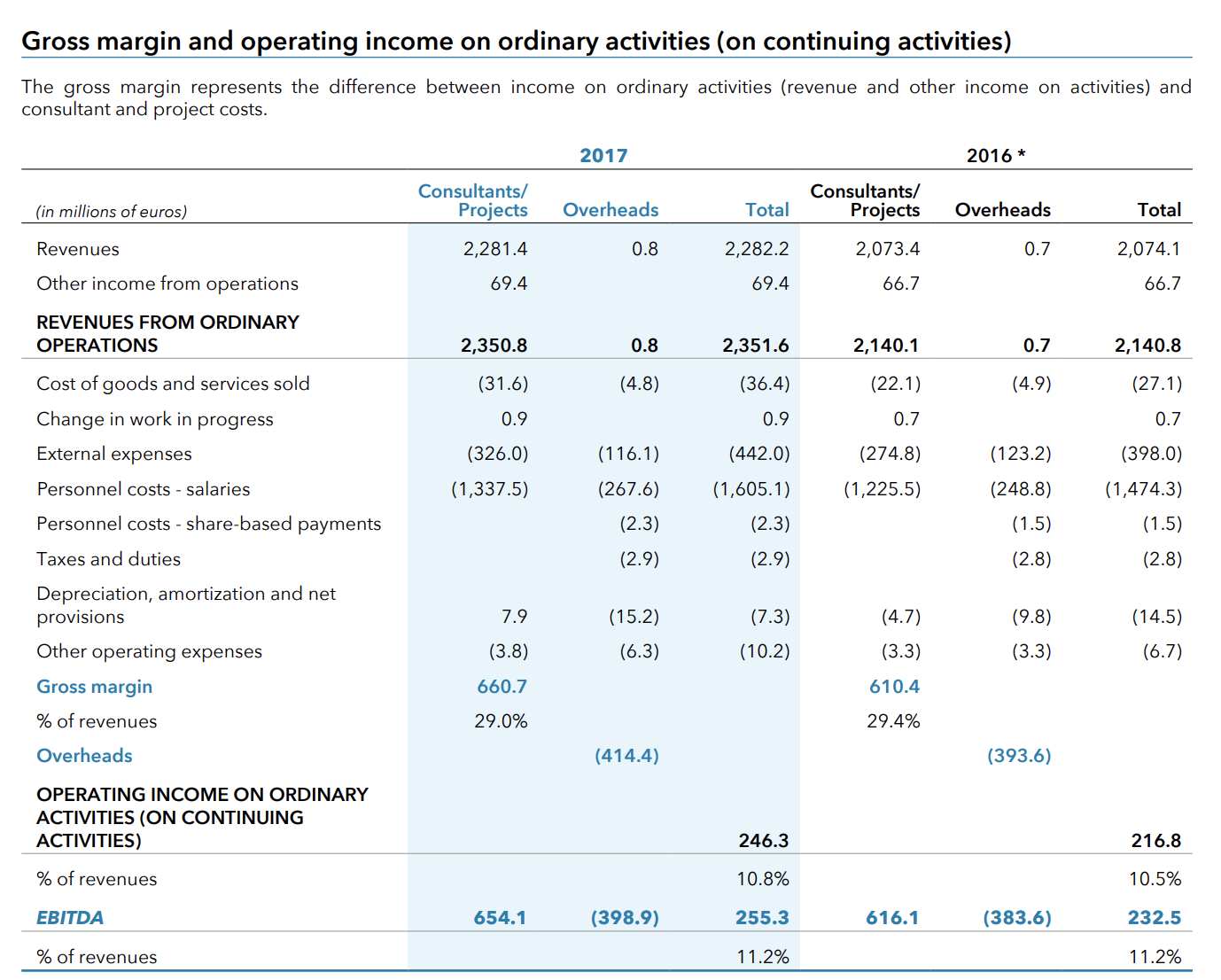
Essentially, it looks like Altran is able to bill its labour at double it’s barely double its cost. Hmm. Anyway, the time is up. I might continue this post or I might not.

Decision Making Journal
This is the first online version of my decision making journal. This is basically what I use myself, but I thought it might be interesting for other too. So I put it here. This was done very fast, in two hours, so please forgive error. To be honest, I am also a bit excited how I gonna rank for “decision making journal” on search.
I have been a fan of the daylio app to track what I actually do with my time from day to day. Now, that I know that I have started to think more about how to actually decide what to do with my time, a result of that is the booking reading article 👌.
Now, I have made an simple version of a decision journal. I have used decision journals before but only in emailing myself, so I thought I structure the data a bit better. Used AirTable for this purpose because I also wanted to improve my AirTable skill. Please forgive errors but do report them - I was setting this up in 2 hours while on 🌊 ⛱🚤 (holiday).
You find the decision making journal here.