Product Strategy for Machine Learning
It isn’t obvious that adding to the plethora of existing material on machine learning is worth the readers or the writers time. The focus of this piece is the product strategist, meaning: he team or individual tasked with allocating within or among products to drive market share, revenue, profitability, growth, or whatever feeds the companies strategy.
It is divided into three parts. First, a closer look at what machine learning or AI really does - namely what a prediction is. Secondly, we consider the options for implementing machine learning in light versions, such as prioritizing which sales lead should be contacted first to full-on implementations such as self driving cars. Third and lastly we take a look at the key aspects of data.
What does machine learning do? A closer look at what a predictions is.
A deceptively simple answer to the question what machine learning does is: “it improves prediction making”. This, of course, is meaningless unless we understand “improving” and “prediction”.
What is a Prediction
Predicting over time
The word prediction can be a bit tricky because of the way it is usually used. A typical prediction that a product managers comes across would be revenue over time.
A “revenue forecast” is nothing but a prediction over time. Revenue could also be predicted among other dimensions, say by product, in any case both are just predictions.
Now, let’s change what is at the axis. Let’s say we are predicting whether or not something is a hot dog or is not a hot dog.
The input for this specific prediction is a picture.
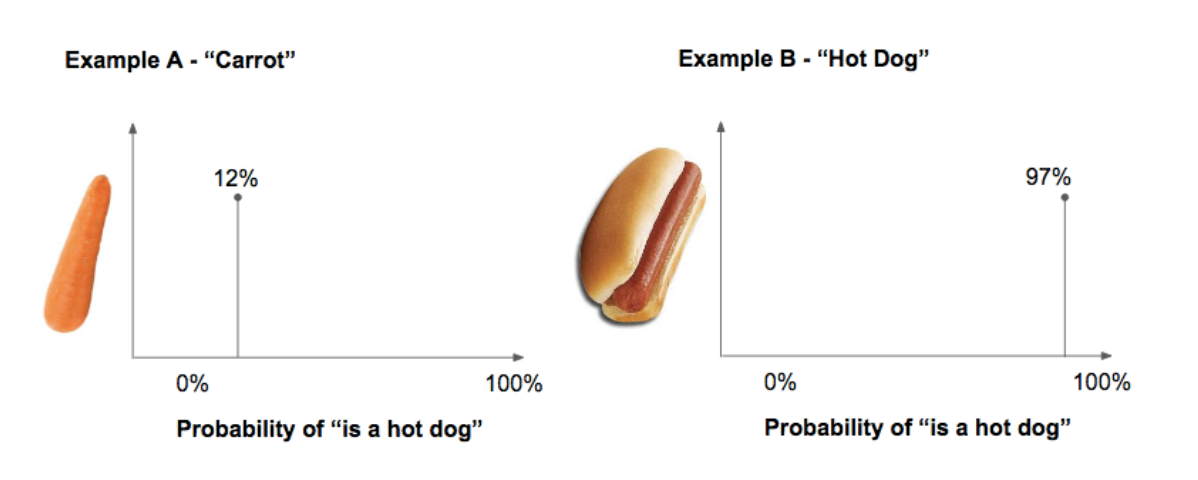
If we look at the X axis, we see that the unit is the probability of the object “is a hot dog”.
Of course, for a human it is easy to differentiate between pictures because humans just happen to be very good at getting and interpreting visual data. In other words, we can see things and know what they are.
But, if you (or any other human) were asked to make the same prediction to give me this information:

It would be much harder for us to predict which of the lines here represent a hot dog. That is just to say, different data can be used to predict the same thing, the probability of whether something “is a hot dog”. Now, back to the picture example.
“Improving” decision making
As a human, when looking at the picture of a carrot and a hot dog, we just recognize which one is which.
But, if I wanted to try to write a program that predicts whether something is a hot dog we might approach it like this: First define a range of typical colours of a frankfurter. Second we define a range of typical colours of bread. Then we define, whenever the ratio of “frankfurter pixels” divided by “bread pixels” is 45% - 75% then the probability that this is a hot dog is 100%.
Now, it is probably obvious that this is highly impractical given the varieties of pictures with hot dogs. Plus, it requires knowledge and an decision-making of how the different factors weigh in.
Machine Learning uses a different approach: after providing a set of correct predictions, pictures labeled as hot dogs (called training data), the computer considers all the factors it finds and weighs them by which factors are most useful in predicting which object is a hot dog and which one is not. This has three consequences:
First, much more and much more complex factors can be processed by a computer than by a human.
Second, we do not know (or more correctly, it is very difficult to re-trace) what the algorithm uses to make it’s prediction. The algorithm might have used our “bread pixels” to “frankfurter pixels” or it might not.
Third, it can be much faster and much cheaper to build a good prediction machine compared to a human. This however depends on the prediction in question and the available data.
How to make a feature out of machine learning? Basic options for implementation.
Machine Learning is about making a prediction. Yet, a prediction has zero value without action resulting from that prediction. How the prediction is taken into action is a separate step. There are different ways of segmenting or thinking about the action part.
Option 1: Offer suggestion to the human
For example, let’s look at CRM system. A CRM is basically a list of potential customers. It is key decision whom the sales representative calls first. A sales representative might only get to make 10 calls per day, so who get these calls matters greatly. Now, let’s say we have trained our prediction machine so it reliably outputs which customer is most likely to buy.
The CRM system might offer the sales representative “10 suggestions” of whom to call each day. These suggestions are simply the predictions of the lead that have the highest likelihood to buy.
Yet the point is, the human still take it’s own decision and can therefore use information that is not captured in the CRM. Say, the sales representative had just been at a conference where he met a potential customer that was very eager to buy. So the sales representative might overrule the machine.
Option 2: Define the workflow
For the second option, let’s assume we have build a workout app. Our goal is to make sure that our users finish the 90 day fitness course. Of course, we want to push our users so that they see results of their workouts. But, we also know that there is a risk of users ending the app use altogether.
Let’s say, we can build a prediction machine on how likely our user is to stop using the app. Data included could for example be how long the user takes per exercise, at what time of the day the workouts happen or a form of user feedback such a question “how exhausted are you on a scale from 1-10”.
Based on the prediction we could than moderate the fitness program for the next day. We could make the app include less of the hardest exercises and instead add some more enjoyable elements. In other words, the human still takes the action but has, in comparison to the first case, no choice in the matter.
Option 3: Let the computer take action
In the most extreme case both the prediction and the action are handled by a machine without a human interfering. The obvious example is a self driving car - it combines prediction and execution. In such an autonomous car there are massive amounts of predictions happening simultaneously - “is the road going left or right?”, “is the child walking on the sidewalk or is it running onto the street?” with relatively few outputs, acceleration, braking and steering, also taken by the machine.
While this is a well known scenario, It’s useful to look at a simpler case. Let’s say we have build a prediction machine for football betting. Following a prediction the machine can bet. Yet, that is not the end: how much can the machine bet? How certain must the probability be to bet how much? Who, at the end, is responsible for the money that could be lost.
In this example the context is only money - these questions which include responsibility get more tricky in other context. Medical diagnoses or the above mentioned autonomous car. Going deeper into these questions far exceeds this piece.
However, allow me one comment - when comparing different solutions it might be useful to be clear about what the ultimate objective if. Or, to be drastic, what is better: 3,500 annual deaths from cars driven by humans or 200 annual deaths from car driven by machines? Note, that I am not arguing that the number of deaths is even the ultimate objective, maybe it is human agency or something else. Clarity about what is being predicted and who takes action is necessary to discuss these questions productively.
How to fuel the machine? Considerations for dataset valuation
When somebody is “doing machine learning” they are not defining how a machine learns but they are teaching a machine that already knows how to learn. That is, because actually enabling machines to learn is a both highly abstract (really difficult) and is software and thereby has virtually zero marginal costs.
Or, take the business perspective: you will not be able to build machine learning algorithms because the talent is extremely rare. And even if you were, you would will not be able to make money because you don’t have the scale to sell them.
Thankfully, machine learning algorithms are widely available in different formats from free libraries to hosted cloud platforms that combine providing, running and storing the algorithm - AWS, Google, Azure and others.
What most “doing machine learning” usually means is gathering, preparing and using data such that you are able to a) generate predictions that are better than the current alternative and b) have ways to let the appropriate action by executed which reduces costs or risk or, even better increases revenue.
There are two sets of data that are vital to the success of this operation. Success means that your prediction is better than what’s currently being done and that the quality of the prediction continues to improve.
Training data - This contains the data you want the prediction machine to use, plus the correct result. For example, if we were to train our hot dog vs. carott prediction machine we might generate source hundreds of pictures and crowdsource the labelling. Mechanical turk is a common tool for this. In the case of picture labelling this is of course quite straight forward because most people know what a hot dog is. That is different for other training - if you think back to the case of the CRM system you would need to have a number of leads with their characteristics plus whether they have bought something in a given time frame or not. That might be difficult data to get.
Feedback data - The second component is feedback data. Not only do you want to train your prediction machine but you want to prevent it from getting worse. This means you need to capture the results of the action which were based on your prediction. Think back to the Fitness App - did the action taken by the app really reduce the likelihood of a user stopping its usage? To judge this you need to know whether a user actually stopped. Or, in other words, you do not want the outcome to “leak”.
The big picture on product strategy for machine learning
Besides the buzz and the speed at which machine learning topics move, the process for the or product strategist can be broken down into a relatively simple questions to ask yourself in the given case:
What is the exact outcome I am predicing?
What is the gained value of the right prediction and what is the lost value of the right prediction?
How will the prediction be translated into action?
With the dataset I have right now, can I predict noticeably better than whatever is doing the prediction today?
What is my path to even better predictions? How will the feedback from actions be incorporated?
If you do not have clear answers to the questions 1-3 you need to get back to basic product management - understand workflows and understand the economics of you user by talking to your users. The machine learning canvas is a good tool to do that. I
f the answer to question 4) is “no”, than you have a data problem. Question 5) should get you thinking about the future of your product on a more strategic level.
Recommended Resources
Hopefully this article gives you an overview to ask good questions to dive deeper, for example "how exactly mathematically does this work?", what is the difference between "machine learning and artificial intelligence"? Without having that question it is difficult to read well. Anyway, below is a set of pieces I want to give respect to for they have helped me.
https://medium.com/machine-learning-for-humans
http://investorfieldguide.com/ash/
https://www.amazon.com/Prediction-Machines-Economics-Artificial-Intelligence/dp/1633695670
https://medium.com/louis-dorard/from-data-to-ai-with-the-machine-learning-canvas-part-i-d171b867b047
https://a16z.com/2017/03/17/machine-learning-startups-data-saas/